
Differential Diffusion: Giving Each Pixel Its Strength
Diffusion models have revolutionized image generation and editing, producing state-of-the-art results in conditioned and unconditioned image synthesis. While current techniques enable user control over the degree of change in an image edit, the controllability is limited to global changes over an entire edited region. This paper introduces a novel framework that enables customization of the amount of change per pixel or per image region.
https://differential-diffusion.github.io
https://github.com/exx8/differential-diffusion
ProteusV0.3
Proteus serves as a sophisticated enhancement over OpenDalleV1.1, leveraging its core functionalities to deliver superior outcomes. Key areas of advancement include heightened responsiveness to prompts and augmented creative capacities. To achieve this, it was fine-tuned using approximately 220,000 GPTV captioned images from copyright-free stock images (with some anime included), which were then normalized. Additionally, DPO (Direct Preference Optimization) was employed through a collection of 10,000 carefully selected high-quality, AI-generated image pairs.
https://huggingface.co/dataautogpt3/ProteusV0.3
Filmgrainer is an image processing algorithm that adds noise to an image resembling photographic film grain. It’s implemented in Python and runs as a command line utility on Linux platforms, installable with pip.
https://github.com/larspontoppidan/filmgrainer
Magic-Me
Unlike common text-to-video model (like OpenAI/Sora), this model is for personalized videos using photos of your friends, family, or pets. By training an embedding with these images, it creates custom videos featuring your loved ones, bringing a unique touch to your memories.
https://github.com/Zhen-Dong/Magic-Me
https://huggingface.co/papers/2402.09368
DARK_GLIGEN GUI
GLIGEN is a novel way to specify the precise location of objects in text-to-image models. I present here an intuitive DARK GUI that makes it significantly easier to use GLIGEN with ComfyUI.
https://github.com/MackinationsAi/gligen-gui_dark
Detect Anything You Want with Grounding DINO |
Cosmopedia is a dataset of synthetic textbooks, blogposts, stories, posts and WikiHow articles generated by Mixtral-8x7B-Instruct-v0.1.The dataset contains over 30 million files and 25 billion tokens, making it the largest open synthetic dataset to date.
https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
Google Gemma Models
running on Huggingface Inference Client
https://huggingface.co/spaces/Omnibus/google-gemma
https://huggingface.co/google
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Today’s deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives.
PIVOT: Prompting with Iterative Visual Optimization
The demo below showcases a version of the PIVOT algorithm, which uses iterative visual prompts to optimize and guide the reasoning of Vision-Langauge-Models (VLMs). Given an image and a description of an object or region, PIVOT iteratively searches for the point in the image that best corresponds to the description. This is done through visual prompting, where instead of reasoning with text, the VLM reasons over images annotated with sampled points, in order to pick the best points. In each iteration, we take the points previously selected by the VLM, resample new points around the their mean, and repeat the process.
https://huggingface.co/spaces/pivot-prompt/pivot-prompt-demo
Introducing Stable Cascade
Today we are releasing Stable Cascade in research preview, a new text to image model building upon the Würstchen architecture. This model is being released under a non-commercial license that permits non-commercial use only.
https://stability.ai/news/introducing-stable-cascade
ComfyUI ProPost
A set of custom ComfyUI nodes for performing basic post-processing effects. These effects can help to take the edge off AI imagery and make them feel more natural. We only have five nodes at the moment, but we plan to add more over time.
Introducing Sora, our text-to-video model. Sora can generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt.
ComfyUI-AutomaticCFG
While this node is connected, this will turn your sampler’s CFG scale into something else. This methods works by rescaling the CFG at each step by evaluating the potential average min/max values. Aiming at a desired output intensity (by intensity I mean overall brightness/saturation/sharpness). The base intensity has been arbitrarily chosen by me and your sampler’s CFG scale will make this target vary. I have set the “central” CFG at 8. Meaning that at 4 you will aim at half of the desired range while at 16 it will be doubled. This makes it feel slightly like the usual when you’re around the normal values.
https://github.com/Extraltodeus/ComfyUI-AutomaticCFG
YOLO-World + EfficientSAM
This is a demo of zero-shot object detection and instance segmentation using YOLO-World and EfficientSAM.
https://huggingface.co/spaces/SkalskiP/YOLO-World
SDXL-Lightning is a lightning-fast text-to-image generation model. It can generate high-quality 1024px images in a few steps. For more information, please refer to our research paper: SDXL-Lightning: Progressive Adversarial Diffusion Distillation. We open-source the model as part of the research.
https://huggingface.co/ByteDance/SDXL-Lightning
SDXL-Lightning
We propose a diffusion distillation method that achieves new state-of-the-art in one-step/few-step 1024px text-to-image generation based on SDXL. Our method combines progressive and adversarial distillation to achieve a balance between quality and mode coverage. In this paper, we discuss the theoretical analysis, discriminator design, model formulation, and training techniques. We open-source our distilled SDXL-Lightning models both as LoRA and full UNet weights.
https://huggingface.co/papers/2402.13929
YOLO-World
This repo contains the PyTorch implementation, pre-trained weights, and pre-training/fine-tuning code for YOLO-World.
This repo contains the PyTorch implementation, pre-trained weights, and pre-training/fine-tuning code for YOLO-World.
YOLO-World is pre-trained on large-scale datasets, including detection, grounding, and image-text datasets.
YOLO-World is the next-generation YOLO detector, with a strong open-vocabulary detection capability and grounding ability.
YOLO-World presents a prompt-then-detect paradigm for efficient user-vocabulary inference, which re-parameterizes vocabulary embeddings as parameters into the model and achieve superior inference speed. You can try to export your own detection model without extra training or fine-tuning in our online demo!
https://github.com/AILab-CVC/YOLO-World
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation
We propose MotionCtrl, a unified and flexible motion controller for video generation. This controller is designed to independently and effectively manage both camera and object motions in the generated videos.

https://github.com/TencentARC/MotionCtrl
AVID is a text-guided video inpainting method
versatile across a spectrum of video durations and tasks
https://zhang-zx.github.io/AVID
Midjourney v6
The Dev Team gonna let the community test an alpha-version of Midjourney v6 model over the winter break, starting tonight, December 21st, 2023.
https://mid-journey.ai/midjourney-v6-release
Midjourney’s V6 Brings New Era of AI Image Generation
Midjourney’s V6, the latest iteration of the esteemed AI image generation tool, has just been released as an alpha release, marking a significant milestone in the realm of artificial intelligence and digital creativity. This new version arrives as a much-anticipated upgrade for enthusiasts and professionals alike, bringing with it a suite of enhancements that promise to redefine the standards of AI-generated imagery.

DragNUWA enables users to manipulate backgrounds or objects within images directly, and the model seamlessly translates these actions into camera movements or object motions, generating the corresponding video.

https://github.com/ProjectNUWA/DragNUWA
From Audio to Photoreal Embodiment
We present a framework for generating full-bodied photorealistic avatars that gesture according to the conversational dynamics of a dyadic interaction. Given speech audio, we output multiple possibilities of gestural motion for an individual, including face, body, and hands. The key behind our method is in combining the benefits of sample diversity from vector quantization with the high-frequency details obtained through diffusion to generate more dynamic, expressive motion. We visualize the generated motion using highly photorealistic avatars that can express crucial nuances in gestures (e.g. sneers and smirks). To facilitate this line of research, we introduce a first-of-its-kind multi-view conversational dataset that allows for photorealistic reconstruction. Experiments show our model generates appropriate and diverse gestures, outperforming both diffusion- and VQ-only methods. Furthermore, our perceptual evaluation highlights the importance of photorealism (vs. meshes) in accurately assessing subtle motion details in conversational gestures. Code and dataset will be publicly released.
https://people.eecs.berkeley.edu/~evonne_ng/projects/audio2photoreal
PF-LRM: Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction
NeRF and poses from 2 – 4 unposed synthetic/generated/real images in ~1.3 seconds.
Generative Models by Stability AI
Following the launch of SDXL-Turbo, we are releasing SD-Turbo.

https://github.com/Stability-AI/generative-models
X‑Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model

https://showlab.github.io/X‑Adapter
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model

https://github.com/magic-research/magic-animate
ai-tube
All the videos are generated using AI, for research purposes only. Some models might produce factually incorrect or biased outputs.
https://huggingface.co/spaces/jbilcke-hf/ai-tube
Personalized Restoration via Dual-Pivot Tuning
By using a few reference images of an individual, we personalize a diffusion prior within a blind image restoration framework. This results in a natural image that closely resembles the individual’s identity, while retaining the visual attributes of the degraded image.
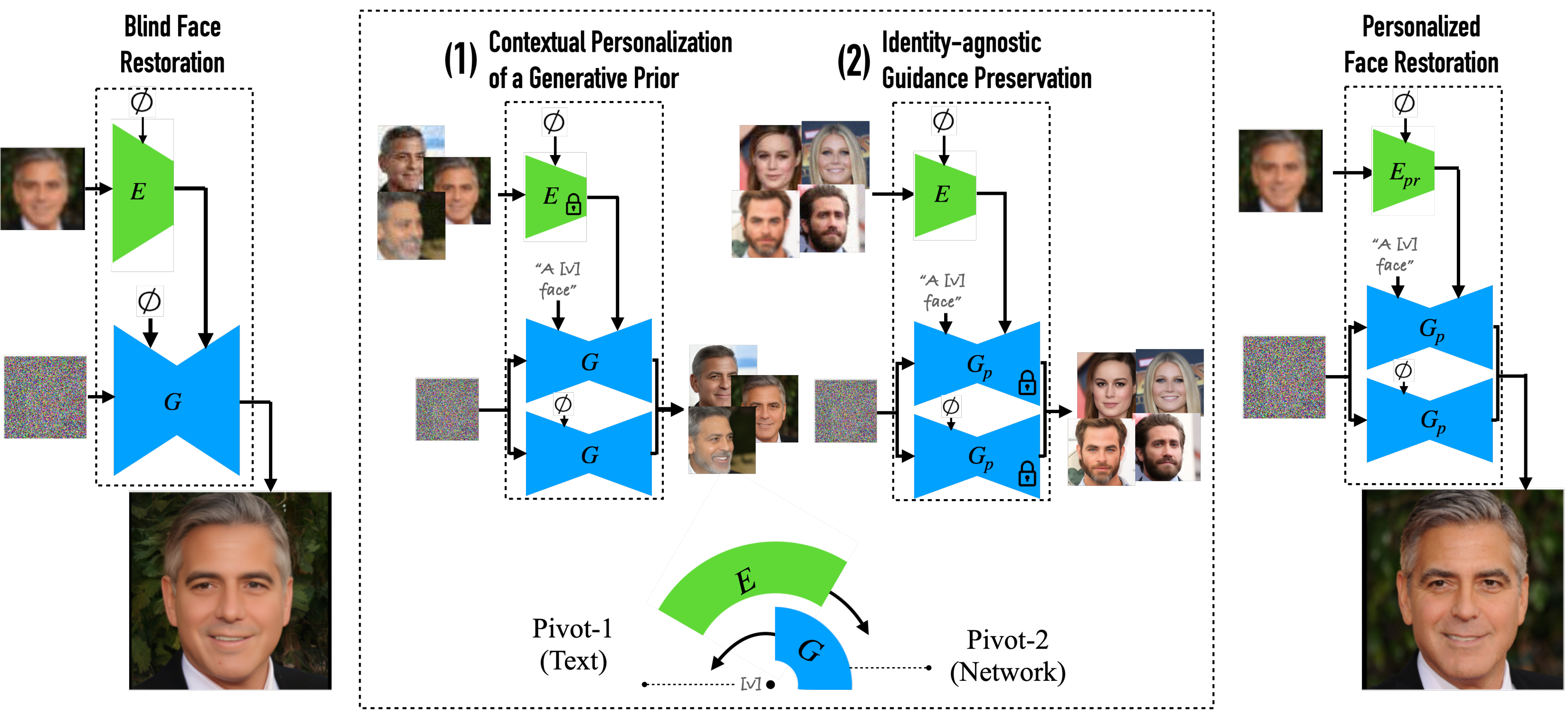
https://personalized-restoration.github.io
SIGNeRF
Scene Integrated Generation for Neural Radiance Fields
https://signerf.jdihlmann.com
Dubbing for Everyone
Data-Efficient Visual Dubbing using Neural Rendering Priors

https://dubbingforeveryone.github.io
Sketch Video Synthesis
Understanding semantic intricacies and high-level concepts is essential in image sketch generation, and this challenge becomes even more formidable when applied to the domain of videos. To address this, we propose a novel optimization-based framework for sketching videos represented by the frame-wise Bézier Curves. In detail, we first propose a cross-frame stroke initialization approach to warm up the location and the width of each curve. Then, we optimize the locations of these curves by utilizing a semantic loss based on CLIP features and a newly designed consistency loss using the self-decomposed 2D atlas network. Built upon these design elements, the resulting sketch video showcases impressive visual abstraction and temporal coherence. Furthermore, by transforming a video into SVG lines through the sketching process, our method unlocks applications in sketch-based video editing and video doodling, enabled through video composition, as exemplified in the teaser.
https://sketchvideo.github.io
https://github.com/yudianzheng/SketchVideo